Text From Github issue https://github.com/yacy/yacy_search_server/issues/578#
Index now near 9 million I am doing a backup.
I hired a 4 CPU cloud to gather main content of my Yacy search engine using only an Android phone.
The Cloud had no swap space defined and had to keep rebooting the cloud server every 3 - 4 days the whole time it was there.
Later on.
I Transferred 150 GB’s to a Windows PC while I reconnected and fixed as well setup my Linux systems back up.
Yacy’s performance on windows.
It ran in ok but a bit slow but its only on a 5400 rpm notebook HDD drive.
I SSH transferred to Linux on New SSD for testing and I could not get yacy to start.
I changed all the locations in the yacy.init still would not start after running in windows.
I ended up in the end taking a yacy.init from another linux yacy install and overwriting the copied windows one and it started.
I checked the index and it was ok, took some time.
I did an Export from 1.924 and an import to the latest github version and have been testing that on a separate SSD in my old I7 PC.
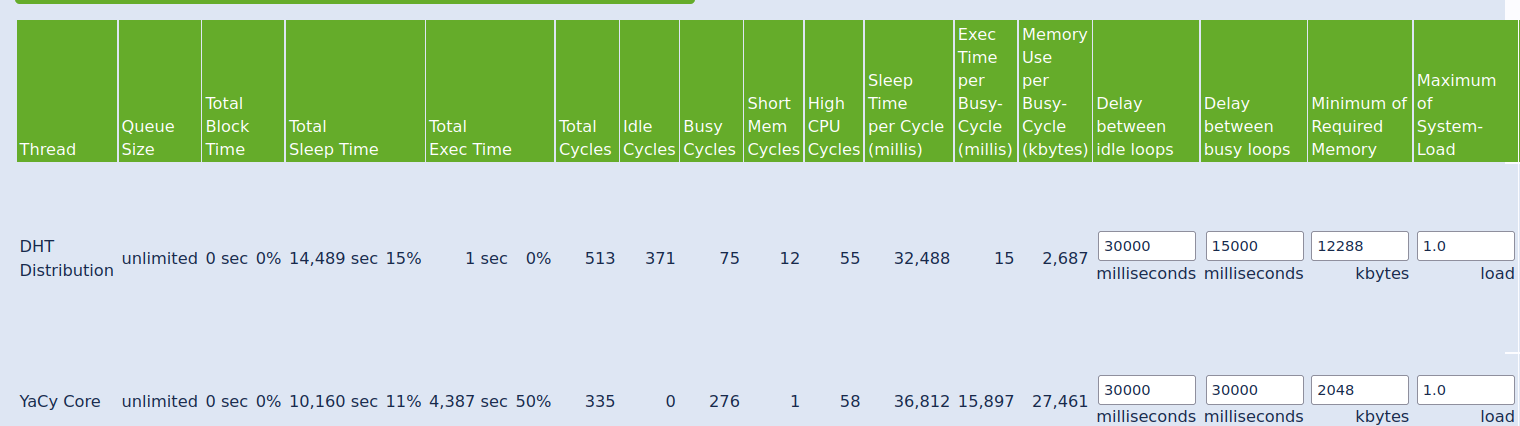
Note: The DHT WORDS was around 6 million and when I had imported it when back to 1.5 million.
The startYACY.sh contents. After experimenting and reading up on minecraft tweaks on the old JAVA Version.
Added java settings seems to help crawling on 10 year old $5 Mainboard with Ubuntu 22.04 Desktop. Also have found if you close all the montors yacy will tend to crawl faster.
Settings tried
JAVA_ARGS=“-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSIncrementalPacing -XX:ParallelGCThreads=15 -XX:+AggressiveOpts $JAVA_ARGS”;
On new Ubuntu 22.04 install yacy would not start until it had a few removed.
JAVA_ARGS=“-XX:ParallelGCThreads=15 -XX:+AggressiveOpts $JAVA_ARGS”;
crawling rate set to 30000 NBN 25 Connection 25 mbs connection.
Pretty much saturated the connection while testing. ( peak internet traffic 218 GB in one day )
-XX:ParallelGCThreads=15 I have tried 4 8 10 while crawling now testing 10 after crawler stopped.
My startYACY.sh
#!/usr/bin/env sh
JAVA=“which java”
CONFIGFILE=“DATA/SETTINGS/yacy.conf”
LOGFILE=“yacy.log”
PIDFILE=“yacy.pid”
OS=“uname”
#get javastart args
JAVA_ARGS=“-server -Djava.awt.headless=true -Dfile.encoding=UTF-8”;
JAVA_ARGS=“-XX:ParallelGCThreads=15 -XX:+AggressiveOpts $JAVA_ARGS”;
#JAVA_ARGS=“-verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails $JAVA_ARGS”;
Have had DNS issues when crawling have made a new blocklist for my pihole.
From Pihole log a DNS typical lookup.
AAAA iframe.dacast.com OK (answered by dns.google#53) CNAME (8.5ms)
AAAA iframe.dacast.com OK (sent to resolver1.opendns.com#53) N/A
A iframe.dacast.com OK (answered by resolver1.opendns.com#53) CNAME (4.2ms)
A iframe.dacast.com OK (sent to resolver1.opendns.com#53) N/A
AAAA www.speldvic.org.au OK (answered by resolver1.opendns.com#53) CNAME (5.4ms)
AAAA www.speldvic.org.au OK (sent to resolver1.opendns.com#53) N/A
A www.speldvic.org.au OK (answered by resolver1.opendns.com#53) CNAME (6.2ms)
A www.speldvic.org.au OK (sent to resolver1.opendns.com#53) N/A
Added more primary and secondary known DNS servers in Pihole settings. Seems to improve crawling.
Testing Crawling a site at depths of 5 6 7 10 20.
Have invalid DNS requests when crawler slows down and it crashes every 2 to 3 hours.
Since adding the blocklist I generated from the pihole logs over 5 days crawling lastes 6 to 7 hours.
Types of domains DNS requests from Yacy to the pihole log and my some in blocklist when crawler slows down.
When the initial crawl is started the DNS lookup is done there are 30000 DNS requests in 10 min of crawling.
After new blocklist and settings changed I had 40 000 DNS requests in 10 min.
I have had Various types of invalid DNS requests when crawler slows down in the Pihole shows them.
AAAA dpird.wa.gov.au?subject= OK (cache) NXDOMAIN (0.4ms)
AAAA dpird.wa.gov.au?subject= OK (cache) NXDOMAIN (1.2ms)
A dpird.wa.gov.au?subject= OK (answered by dns.quad9.net#53) NXDOMAIN (1.2ms)
A dpird.wa.gov.au?subject= OK (sent to dns.quad9.net#53) N/A
customer_name.atlassian.net"
charts.gitlab.io<
www.mumble.info">mumble<
ayearofsprings.crd.co">a
maven.google.com"
toasters.example",
www.apple.com"
apptwo.company.com"
www.yosoygames.com.ar%5c
www.example-dsp.com',
www.example-ssp.com',
buyer2.com',
www.example-dsp.com'
www.another-buyer.com'
www.some-other-ssp.com',
risc.example.com",
A gayle bowen (klgates.com)
Crawling speed set at 30000
Had system loan indicator % up at 1200… 8 is normal for my cpu. hit the reset.
Not sure where the fault is happened several times.
Also there was some debug msg you system does not have enough free memory to debug.
When crawling at maximum speed for some time my 6 GB Swap file filled up…now has 32 GB swap space.
Also there was some debug msg you system does not have enough memory to debug.
When crawling maximum speed crawler ques keeps files open like trying to download the zip and other file contents directly.
Also had socket error once or twice when pushing Yacy.
Tried this
Thread Pool Settings:
Crawler Pool 4000
Robots.txt Pool 4000
httpd Session Pool 4000
With new blocklist the crawler was near Zero but there was 4000 items stuck in Thread Pool.
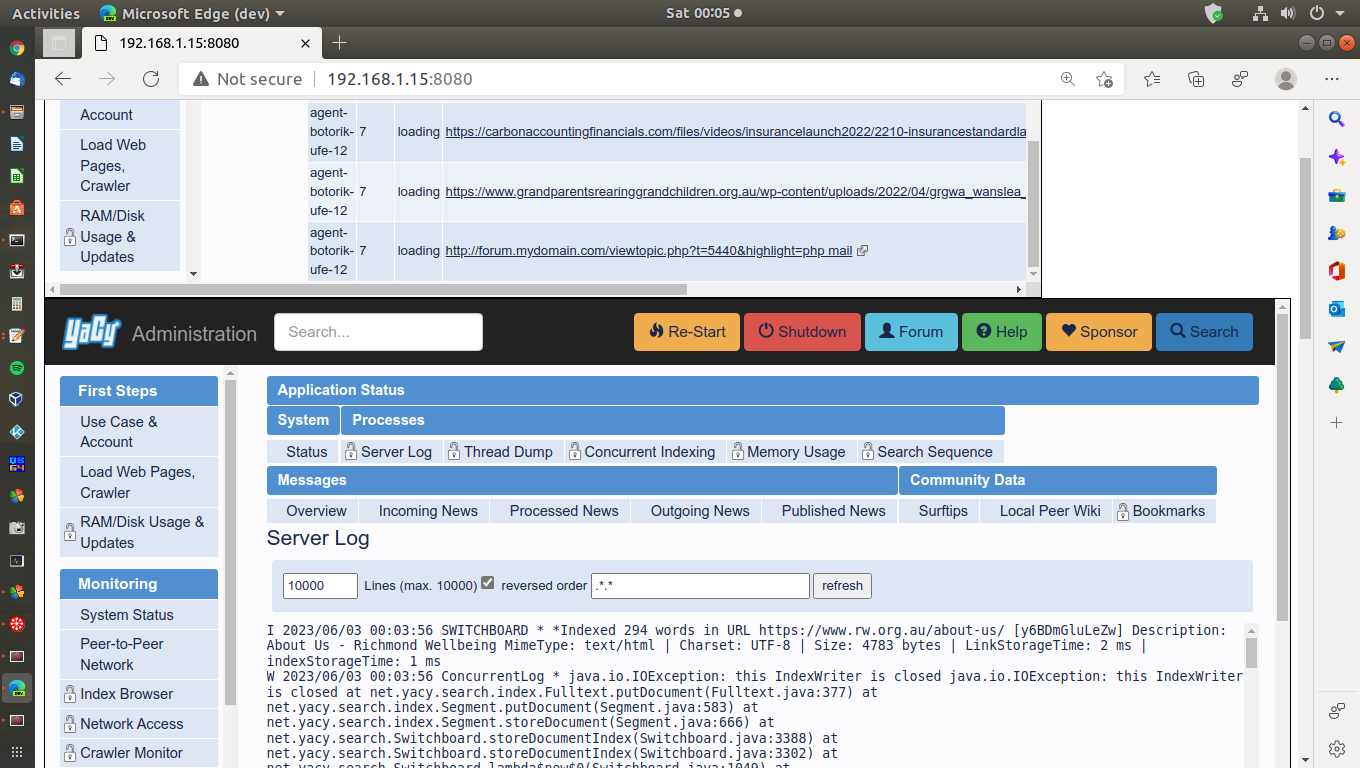
I checked the Local Crawl list on the crawler monitor page and found a discource forum giving the 4 dot loading like keeping the connection open waiting when connecting in browser. I have struck that with a browser on the Nextcloud forum as well.
Also Upseting the DNS Server causes Crawling to come to a dead stop.
Tried upgrading Yacy 1.924 to latest.
Did the Export XML (Rich and full-text Solr data, one document per line in one large xml file, can be processed with shell tools, can be imported with DATA/SURROGATE/in/)
Lost DHT WORDS.
Ended in lost DHT Words.
New System
YaCy version: yacy_v1.926_202304041204_1c0f50985
Uptime: 0 days 00:34
Java version: 1.8.0_362
Processors: 8
Load: 0.98
Threads: 52/14, peak:107, total:430
Thread Dump just after starting yacy with crawl depth 7.
THREADS WITH STATES: BLOCKED
Thread= qtp261650860-104-acceptor-1@1c987884-httpd:8095@7bf9b098{HTTP/1.1, (http/1.1)}{0.0.0.0:8095} id=104 BLOCKED
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:233)
at org.eclipse.jetty.server.ServerConnector.accept(ServerConnector.java:388)
at org.eclipse.jetty.server.AbstractConnector$Acceptor.run(AbstractConnector.java:702)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:882)
at org.eclipse.jetty.util.thread.QueuedThreadPool$Runner.run(QueuedThreadPool.java:1036)
at java.lang.Thread.run(Thread.java:750)
Possible web cache issue. Seems to go away when not storing to web cache.
Testing on
Started yacy version 1.924/9000
Crawler set to 400 ppm and left running.
Crawler stopped and yacy was not responding. Happened twice over a few days.
Looked in and deleted…
/DATA/INDEX/freeworld/QUEUES/CrawlerCoreStacks
%20www.ischs.org.au-#XxMjNQ.80
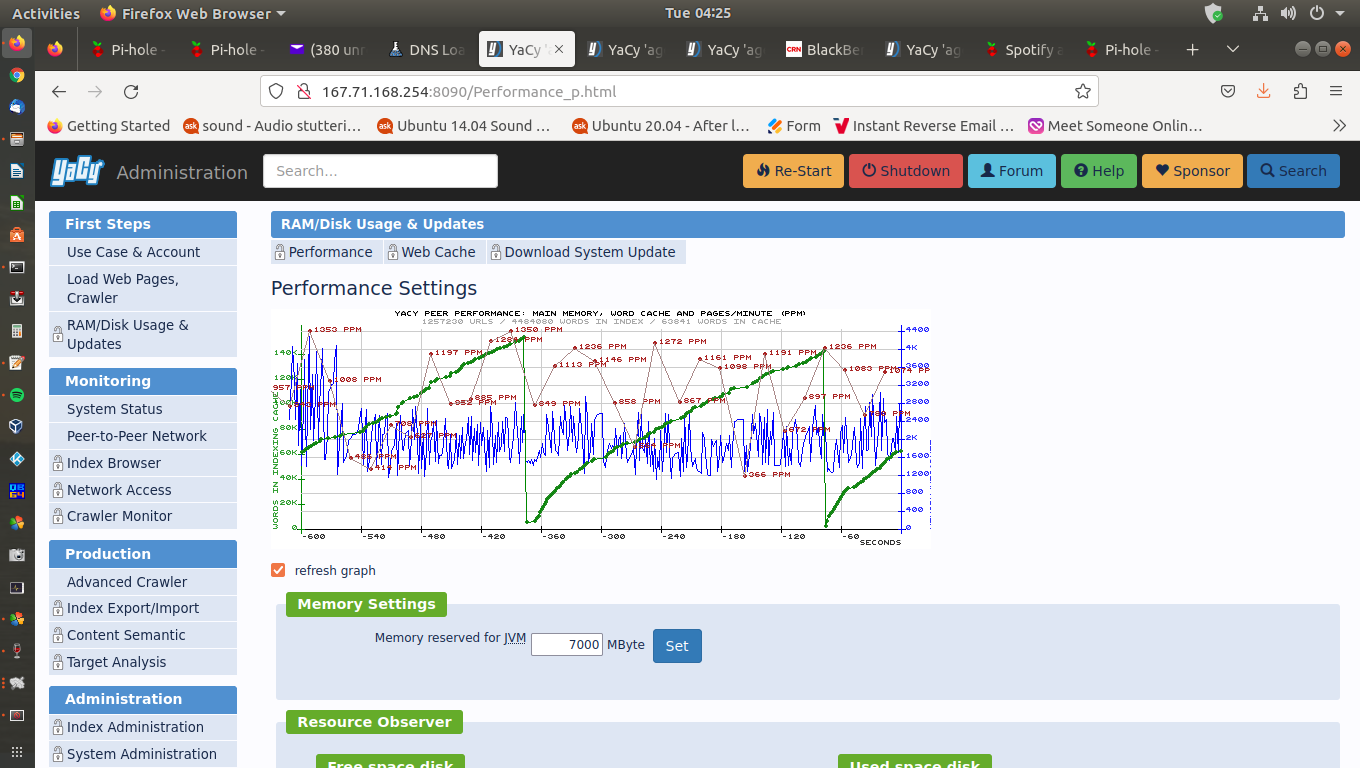
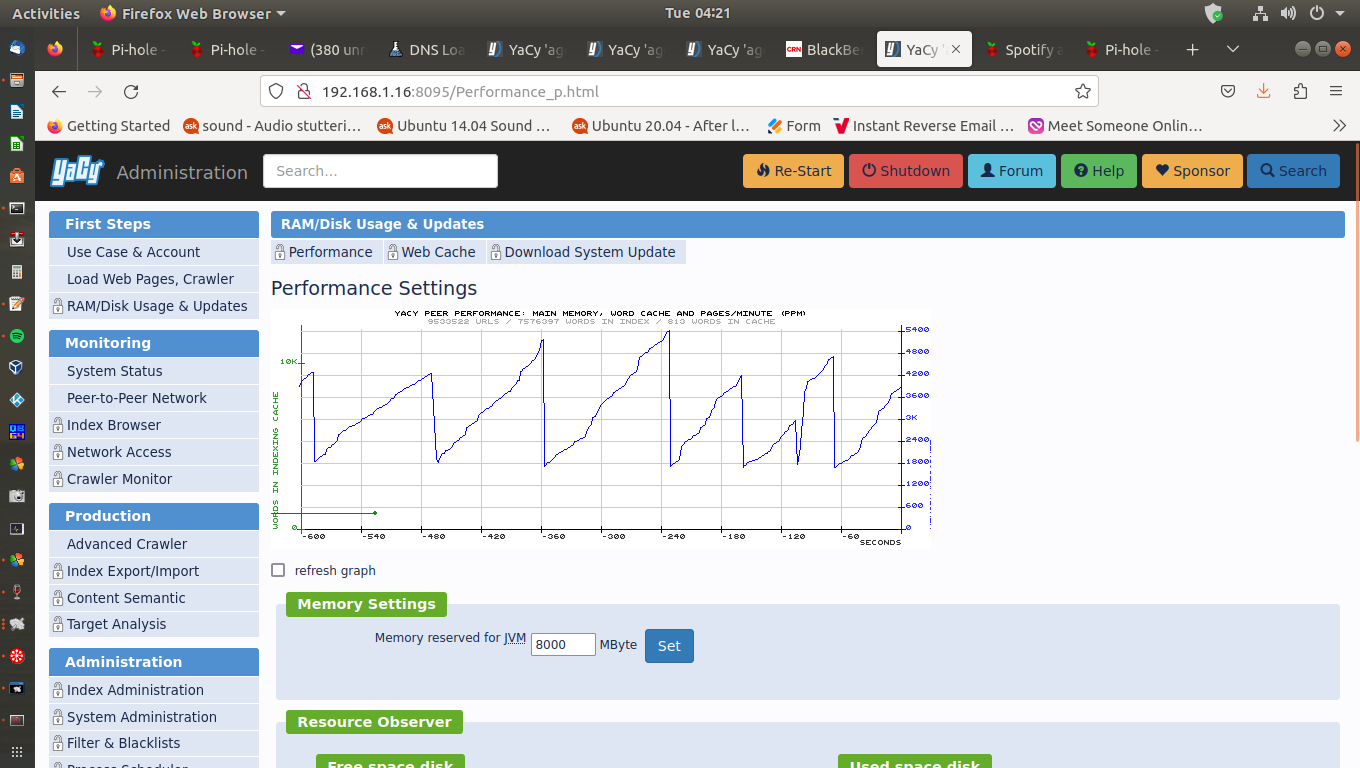
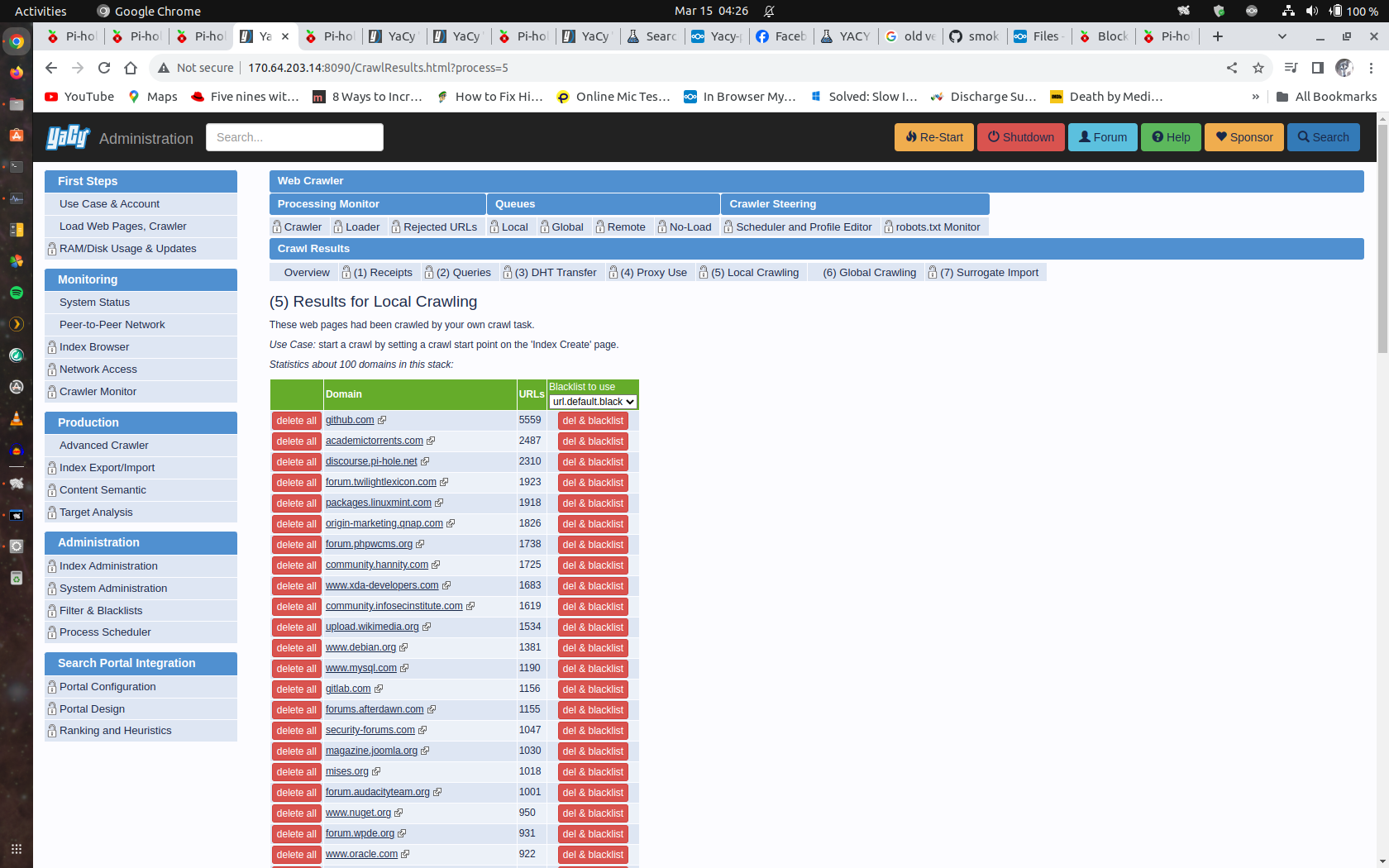
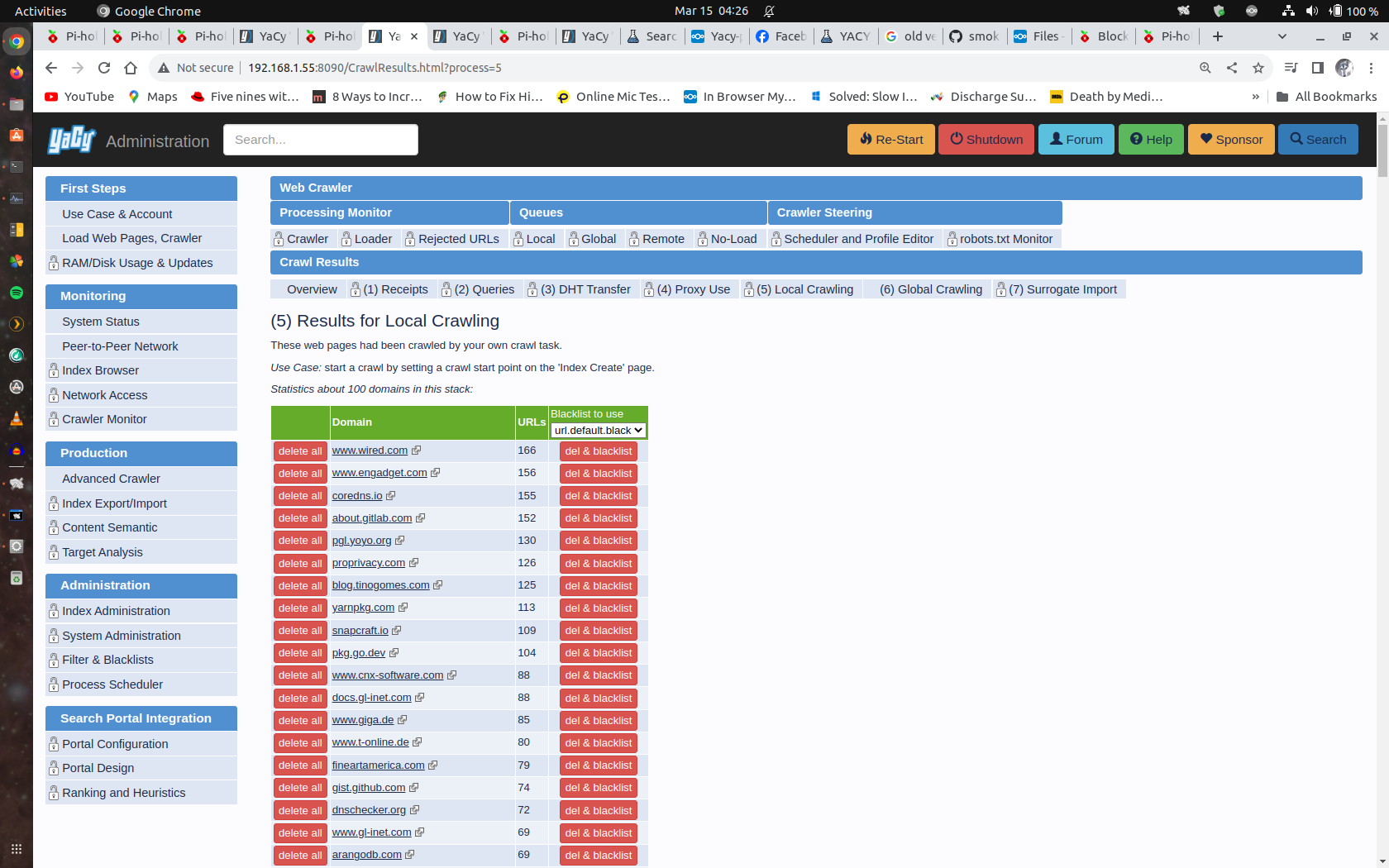
Will continue testing index just hit 8 Million from 6.5 million virtual cloud system.
I tried Dnsmasq server to cache the DNS for several days and found it reduces the peak DNS load by 50%.
I then tried installing the pihole on the local machine but am having DNS issues so a backup and fresh install is in order.
Many Thanks for reading.