Having much bigger Hardware now - and much more network power, I would like to make my boxes sweat, but:
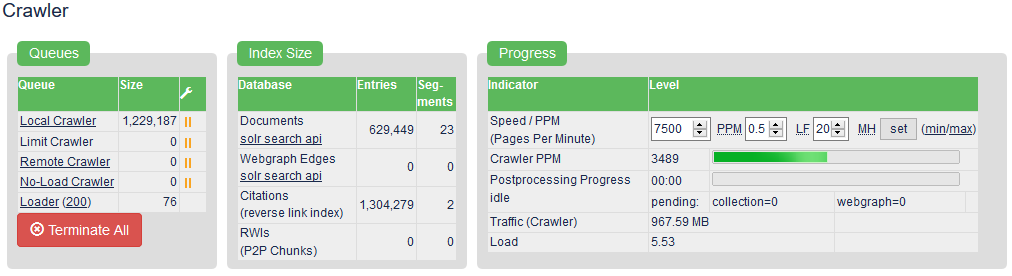
The crawler does not reach significantly more than 1000 PPM, the felt average is 50.
Starting more crawls in parallel does not help. What does limit the performance? What are the tricks to sppeed up?
Should I use a DNS Jumper ? (currently I use 1.1.1.1 or 8.8.8.8) as my ISP (Swisscom) constantly suspects me of being a virus… …when havin a lot of dead inks in my starturls.
I don’t think the DNS have anything to do whit that, and I can advice you OpenNIC as DNS instead of Google and Cloudflare
Also keep in mind you must not crawl too fast to not overload the websites, it would be like a ddos and everyone would start to block the yacybot crawler after that.
YaCy limits bandwidth per domain by 120 pages per minute. We try to do a domain balancing, so crawling of several domains at the same time speeds up the crawling. But that means with 10 different domains in the crawl queues, you can only reach 1200 ppm.
To spee up, you just need more different domains.
I have a list of 9000 universities worlwide. all different domains. It started with up to 3000 ppm, but broke down to 5-20 after 2 hrs. Crawls started afterwards look like they have to wait / are enqueued.
Lots of urls hit my blacklist, which has all the commercial crap on it like tumblr, facebook twitter and amazon. I got the impression, that many asian URLs answer fairly slow, so IMHO a simple increase of parallel threads should help, but where is the parameter?
CPU (12 Cores) is at 15%, Network at 5% and Disk at 3%, 30 GB Ram allowed, but only 20GB used.
3.200.000 at the Local Crawler queue.
DNS definitely is a suspect. Too many unknown domain lookups lead to lockouts after a few hours. OpenNIC is a good hint - thx. I will try. Have a look at DNSJumper.
I am thinking about a parallel setup: 10 YaCy instances on one machine, solrs connected. If it works: Increase the number of machines. Unfortunately the Index browser does not work anymore it there is several solrs connected. Even worse: It depends, which YaCy Instance you use for searching. Results are totally different. It looks like the search mostly always use the local solr for searching.
After a reboot, PPM starts high (~uo to 300-500) but falls down to ~10 after a few minutes.
I crawl a list of 1Mio. different domains. I guess, as many of them time out, I should have lot more crawler queues. How can I increase the number?
P.S.: I use OpenNIC now, but w/o a change in performance.
I guess the DNS is the problem. Having several million different domain names in the queue will surely be throttled by your DNS provider of your setup.
Has anyone thought about this issue?
I am afraid the only solution is to run at least one DNS (cache) server by yourself.
Any experience or recommendations here, e.g. what software / setup to use?
Thx a lot. I was thinking about running a local bind dns, but now I am reading the docs for unbound.
I guess I have to load the domain/IP Address data as “domain overrides” somehow first…
I run a local unbound now with a list of public DNS servers in round robin mode. 250K different domains crawl at 1500 PPM now. Important: Reboot YaCy first, otherwise you get out of memory or get stuck in any other way.
I would like to share my unbound.conf here as this speeds up things incredibly.
The trick is “round robin” (rrset-roundrobin: yes) and a huge list of DNS resolvers (resolver.inc):
command to generate the resolver.inc by downloading a great list from the web:
curl -s "https://public-dns.info/nameservers.txt" | perl -e 'while(<>){chomp;print "forward-addr: " . $_ . "\n";}' > resolver.inc
`
The main reason to have the cache was, that Java had (has?) a well-known DNS cache deadlock bug. So Crawling was deadlocked in very old YaCy versions and we made a workaround to the jvm DNS cache (which also exists!).
I have no idea, what I am doing wrong. I run 3 different independent data centers in 2 countries (DE and CH). 3 different ISPs.
It’s all the same with all sites. I tried everything. Physical machines, VMs. 100GB RAM. All the same.
Lists of single domains as starturls now run at 200 PPM (level 0). My Instance with some hundred different news starturls (level 3) crawl at ~1200 PPM. My unbound service is very busy during round robin with several 100 DNS resolvers) as expected. Mostly factor 10 times more than java.
I run ipfire as firewall on a dedicated machine. Do I need more sophisticated network equipment? Latency issue?
I would think at some point, a limiting factor would be the speed of the servers and networks the website being crawled are hosted on.
Crawling hundreds or thousands of pages a minute seems quite exceptional to me, considering that during ordinary web browsing, in my experience, it often takes quite some time, sometimes a full minute or more for ONE website to respond.
That could be due to heavy traffic, congestion on the network, distance to the server, speed of the server, etc. (Another bottleneck on the network could be government surveillance of the internet backbone. Presumably.)
ok I have 450mbit and used a wide crawl with many hosts…
The balancer scaled up to about 50 loading threads … while there are 200 are reserved and 150 had not been used because the balancer stopped from loading so far.
 …when havin a lot of dead inks in my starturls.
…when havin a lot of dead inks in my starturls.