I put a list of forums some 478 url’s today to test my yacy with pihole running on the same pc.
I started the crawl of the sites at a depth of 1 this was ok and fast for a short time, it would slow down to about 50 ppm.
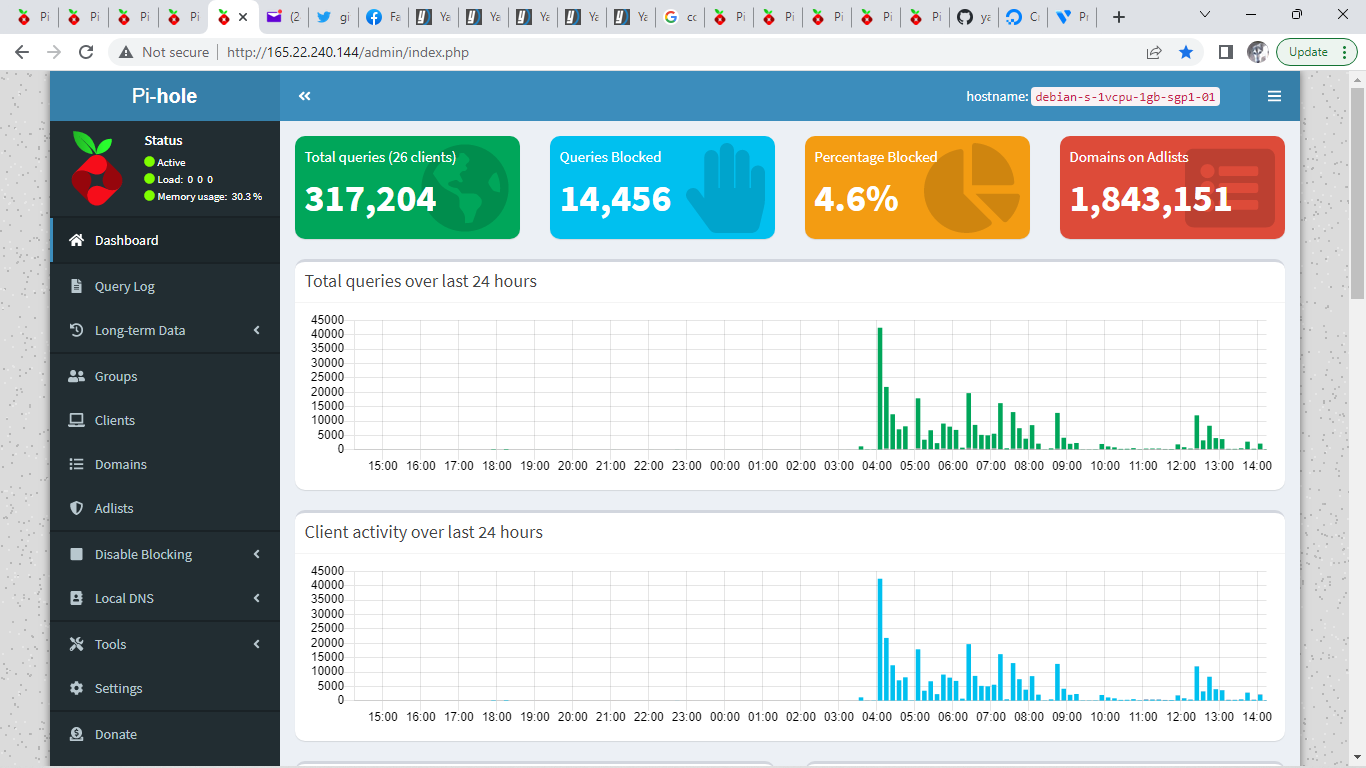
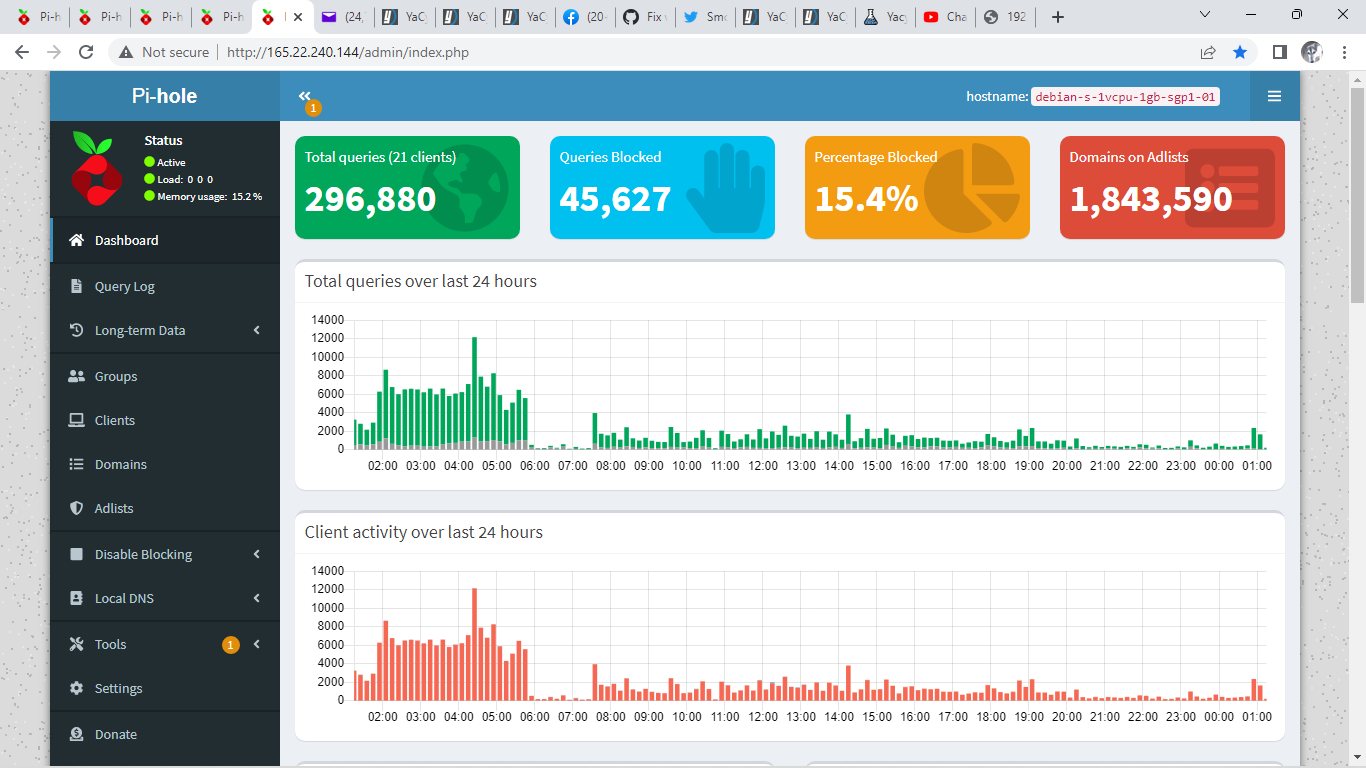
I started to check the logs on yacy and the query page on the pihole to black list problem sites.
There where a number of sites that where asking for 10 second crawl delay so they got blacklisted in one way or another.
I kept blacklisting sites and restarting the crawler a many times.
I also was clearing the webcache and robots cache.
It took me about 2 hours to have the crawl finish properly.
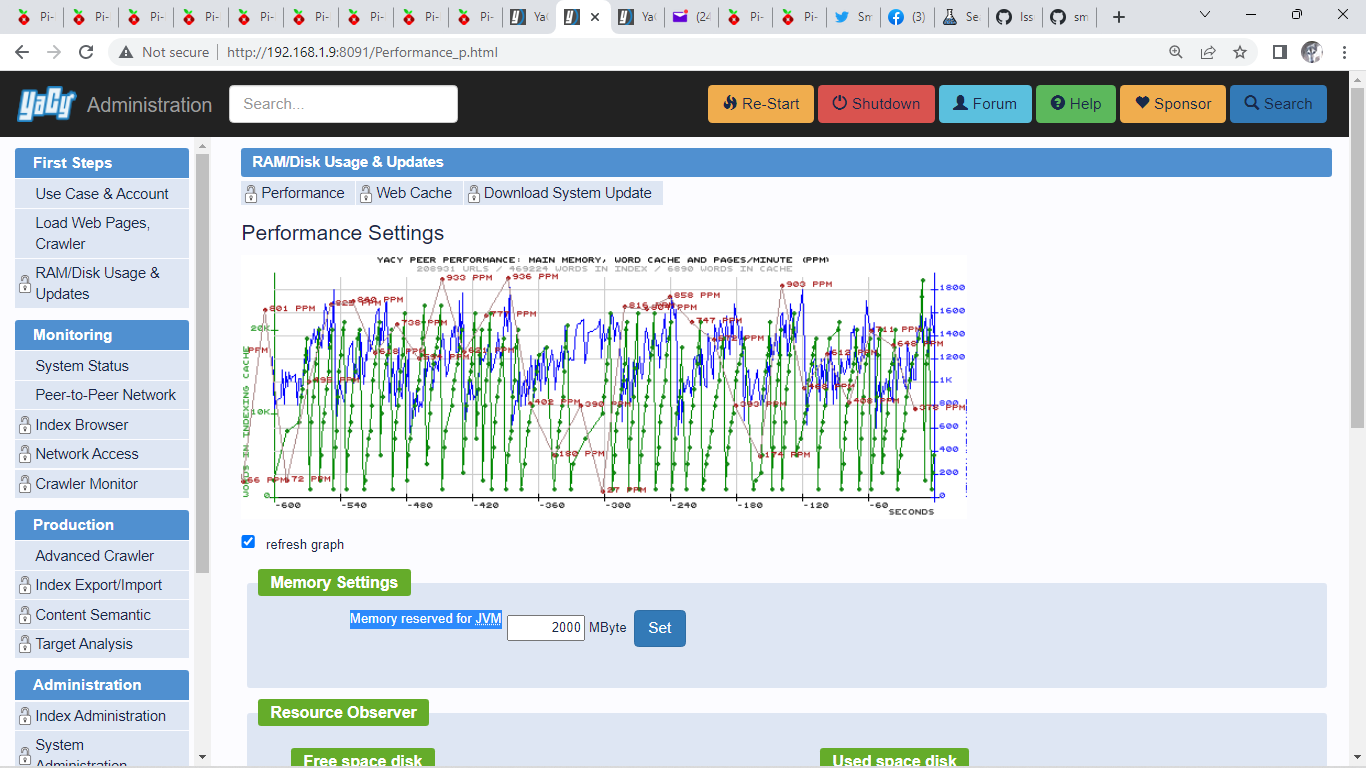
Its been crawling for about 4 hour now so far with my internet connection maxed out. (see pic).
The CPU in the Notebook im using is an i5 released 12 years ago with a HDD.
I did an experiment in 2017 with yacy and a raspberry PI 3 B there is a hosts file listing there.
I found this information on a YaCy search engine I have.
The hosts file listing may help the current project.
meanwhile I added a dns lookup throttling which reduces the number of requests once there are more than 50 simultaneous requests. I hope this will also protect routers at home as well against request flooding.
Sure go ahead will test.
Note I have 5 piholes running at the same time.
I have the concurrent 150 warning a lot less now.
My old router could only handle 75 queries a second my new one about 100 quieres a second.
The current settings takes 10 min to cache dns on a list of 480 sites not normal sort of a crawl?
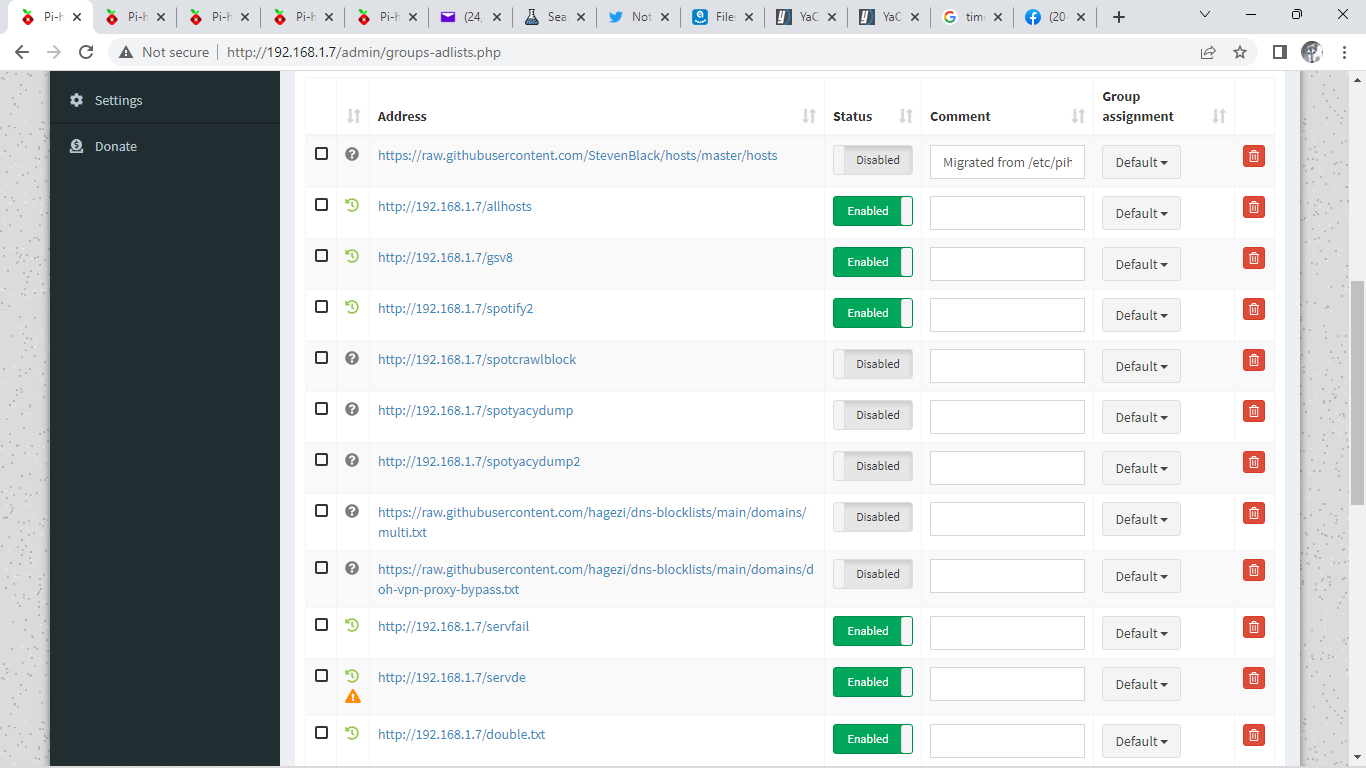
If anyone wants to use my lists in there Pihole you are welcome to try them.
You copy the list to the Piholes /var/www/html folder and point the adlist to it eg http://192.168.1.7/allhosts