Hello,
we just discovered YaCy as an alternative to OpenSearchServer. We want to use it for prividing a portal search on our webpage https://www.ffh.de
YaCy is already installed an running. Also the crawler is able to find pages and does add these pages to the index. But not all subpages seems to be crawled. Even the craling depth is set to 4 what should be high enough.
i.e. the subpage Aktuelle Nachrichten & Sport aus Hessen – FFH.de is not crawled, even it is linked in the main menu on every page. The Regex does match too.
What could be the reason for this? Within the log no details regarding this URL are displayed.
An additional question: How does YaCy handle canonical urls? If more than one page has the same canonical URL, does it only the main page to the index?
Thanks.
1 Like
Hi, welcome here!
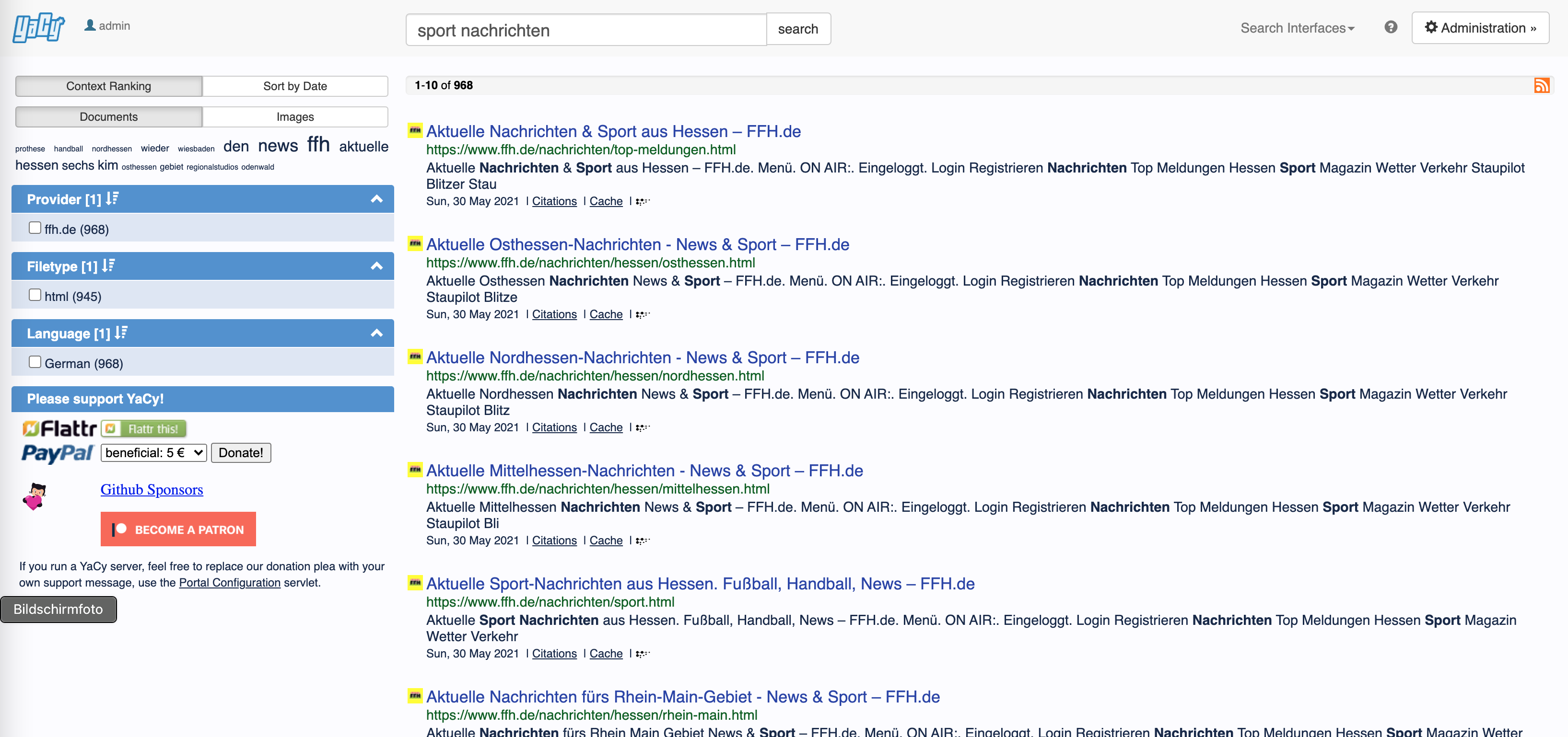
I tried also to crawl ffh.de in portal mode using the advanced crawler setting only the flag “restrict to start domain” and got 2171 pages. In those set of pages, also the nachrichten & sport page appears:
however, there had been a large number of pages which had not been loaded (about 700) and all of then had a 429 “too many requests” error. I guess your test had similar results and you did not get the nachrichten & sport pages because they had been among the 429 error pages.
So … YaCy has a strong crawler throttler which limits to at most two pages per second (4 in most recent YaCy versions). The limitation is on purpose to behave nice to web pages (and their administrators  ) but people also constantly complain about slow indexing speed - which is on purpose.
) but people also constantly complain about slow indexing speed - which is on purpose.
In your case the crawling speed was obviously not slow enough!
There are two solutions:
- either reduce the crawling speed (in the crawler monitor, set PPM)
- or you as the administration can allow a higher access speed to void the 429 error
To your question about canonical urls: yes, the canonical tag is evaluated if you set the corresponding flag in /IndexSchema_p.html
In that schema look out for “canonical_equal_sku_b”. This sets a “true” flag in case that a page is canonical to itself - which makes it “the canonical” page. Now you can use that flag in the ranking rule on page /RankingSolr_p.html to boost up pages which have that flag assigned. The effect is then that non-canonical pages are still inside the search result, but ranked lower.
Thanks for the support! The !429 Too many Requests" status code is triggert, when too many uncached pages are generated for a singe specific IP. I already reduced the Crawler to 60 pages per Minute, but it does not realy fit. Not it is working fine and 1000+ documents are fetched.
Also checked the canonical_equal_sku_b. But I can’t see it in the complete metadataset of an document. Also it is not listed in the “Solr Boosts”. I would like to add it on “Filter Query” like canonical_equal_sku_b:true. So only URLs which are canonical would be listed. As all of our URLs have at least one canonincal URL this would perfectly fit the requirement.