I have Yacy running v1.924_20210209 running on a FreeBSD host.
It starts fine, has already crawled some sites and is connected p2p.
But each time I start it, it stops after some hours and I can’t find anything relevant in the logs at DATA/LOG except maybe for a threaddump.txt file.
The threaddump.txt has mtime of 10h02
The last yacy00.log has mtime of 10h07
Started it again and it stopped after a few hours.
The last lines outputted were:
I 2022/04/17 17:42:16 STACKCRAWL URL 'https://github.com/flathub/org.onionshare.OnionShare' file extension is not supported and indexing of linked non-parsable documents is disabled.
I 2022/04/17 17:42:16 REJECTED https://github.com/flathub/org.onionshare.OnionShare - URL 'https://github.com/flathub/org.onionshare.OnionShare' file extension is not supported and indexing of linked non-parsable documents is disabled.
I 2022/04/17 17:42:16 REJECTED https://www.githubstatus.com/ - url does not match must-match filter (smb|ftp|https?)://(www.)?(\Qgithub.com\E.*)
I 2022/04/17 17:42:16 REJECTED https://github.githubassets.com/images/modules/profile/badge--acv-64.png - url does not match must-match filter (smb|ftp|https?)://(www.)?(\Qgithub.com\E.*)
I 2022/04/17 17:42:16 REJECTED https://docs.github.com/categories/setting-up-and-managing-your-github-profile - url does not match must-match filter (smb|ftp|https?)://(www.)?(\Qgithub.com\E.*)
I 2022/04/17 17:42:16 REJECTED https://education.github.com/ - url does not match must-match filter (smb|ftp|https?)://(www.)?(\Qgithub.com\E.*)
I 2022/04/17 17:42:16 REJECTED https://lab.github.com/ - url does not match must-match filter (smb|ftp|https?)://(www.)?(\Qgithub.com\E.*)
I 2022/04/17 17:42:16 REJECTED https://support.github.com/?tags=dotcom-footer - url does not match must-match filter (smb|ftp|https?)://(www.)?(\Qgithub.com\E.*)
I 2022/04/17 17:42:16 SWITCHBOARD Excluded 14 words in URL https://github.com/proletarius101
I 2022/04/17 17:42:16 Fulltext indexing: L6rZksS6MKD4 https://github.com/proletarius101
Killed
The first time it happened with only three or four crawlers.
At later times, about eight were running.
Today, there was some error output:
at net.yacy.cora.federate.solr.connector.MirrorSolrConnector.add(MirrorSolrConnector.java:204)
at net.yacy.search.index.Fulltext.putDocument(Fulltext.java:370)
at net.yacy.search.index.Segment.putDocument(Segment.java:556)
at net.yacy.search.index.Segment.storeDocument(Segment.java:639)
at net.yacy.search.Switchboard.storeDocumentIndex(Switchboard.java:3468)
at net.yacy.search.Switchboard.storeDocumentIndex(Switchboard.java:3382)
at net.yacy.search.Switchboard$7.process(Switchboard.java:1058)
at net.yacy.search.Switchboard$7.process(Switchboard.java:1054)
at net.yacy.kelondro.workflow.InstantBlockingThread.job(InstantBlockingThread.java:72)
at net.yacy.kelondro.workflow.AbstractBlockingThread.run(AbstractBlockingThread.java:82)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.lucene.store.AlreadyClosedException: this IndexWriter is closed
at org.apache.lucene.index.IndexWriter.ensureOpen(IndexWriter.java:680)
at org.apache.lucene.index.IndexWriter.ensureOpen(IndexWriter.java:694)
at org.apache.lucene.index.IndexWriter.updateDocument(IndexWriter.java:1613)
at org.apache.lucene.index.IndexWriter.updateDocument(IndexWriter.java:1608)
at org.apache.solr.update.DirectUpdateHandler2.updateDocOrDocValues(DirectUpdateHandler2.java:969)
at org.apache.solr.update.DirectUpdateHandler2.doNormalUpdate(DirectUpdateHandler2.java:341)
at org.apache.solr.update.DirectUpdateHandler2.addDoc0(DirectUpdateHandler2.java:288)
at org.apache.solr.update.DirectUpdateHandler2.addDoc(DirectUpdateHandler2.java:235)
... 45 more
Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
'l like to answer about memory, but it seems that I cannot start anymore the service.
When tried to start it, got
>> YaCy started as daemon process. Administration at http://localhost:8090 <<
70_search@70_search:~/yacy $ W 2022/04/18 23:41:57 Cache file and metadata size is not equal, starting a cleanup thread...
W 2022/04/18 23:42:00 BROWSER System unknown
W 2022/04/18 23:42:09 YACY rejected bad yacy news record (3): attributes length (1026) exceeds maximum (974)
W 2022/04/18 23:42:40 YACY rejected bad yacy news record (3): attributes length (1026) exceeds maximum (974)
Control+C
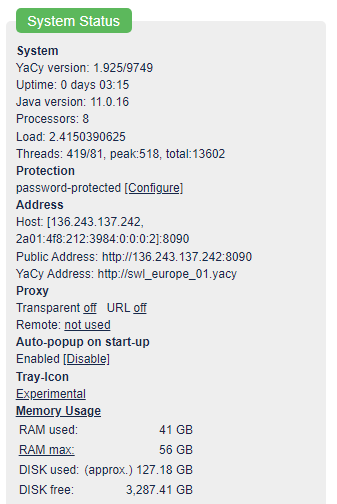
YaCy is quite RAM hungry and, as far as i know, it’s by design. I struggle with RAM all the time. It occupies only the amount of RAM specified in “Maximum Used Memory”, so increasing this value will help. Sometimes also ‘Database Optimisation’ helps, but it takes some time to run.
Solution I’m thinking of is to use external solr (on the same machine), which should help, but I didn’t have time to do so yet.
I have experimented with YaCy for about a year and half now, time to time so angry, I think I’ll leave it, but the concept seems good and I didn’t find any similar project. Implementation is lazy, resources hungry and buggy, but it still make sense for me. So let’s report bugs and push the developers to fix them.
I am starting to have the same issue. works great, gets crawling done without issue. I started to have the problem with system stopping when I activated the Process Scheduler. I had 7 re-crawls activated at different hours of the night. Last night I took it down to 2 process’s, Yacy hung again. I an going to turn all processes off to see what happens tonight.
No, I’m not a Java man, never liked Java because it’s so demanding in resources. And I’ve only seen a few Java apps that really worked well.
Go would make a very good replacement for the project.
From the web page you’ve cited, there’s this:
Why is this not done by default?
YaCy wants to be nice to the average computer user and their systems. Modern computers have 512MB RAM or more. We believe that 96MB for YaCy as default is a good tradeoff between performance and resource allocation.
Well, in the Memory reserved for JVM there was 600MB, there’s 900MB now. I have plenty of resources in my VPS, if another one was another Java one it couldn’t run.
Java is great for hardware sellers and consulting companies charging by the hour.
recently, out of frustration, i bought 32GB of ram and put it into yacy machine. yacy works really nice, now.
well… java.
probably not a solution for everyone, but handful of ram really helps the yacy speed and responsiveness.
there is even script restartYACY.sh, which stops and starts the instance again. i use it from cron, every day, since the instance tended to freeze after few days.
Try increasing the memory, I found it unreliable if set to anything less than the max. I’ve got mine on a 128gb virtual machine on a physical box with 256gb of RAM.